Two AIs in a terminal arguing
Picture this: Claude Code in your left terminal writing the code. Codex in your right terminal reviewing it. A bridge in the middle lets them talk directly. You sit back and watch them argue about how your code should change.
Not sci-fi. An open-source CLI called loop is already doing it. Author Axel Delafosse ran it in production and noticed something surprising: when two different AIs independently arrive at the same code review verdict, the team adopts the suggestion 100% of the time.
Not because AI is always right. Because two completely different models — different architectures, different training data — converging on the same conclusion is a far stronger consensus signal than any single model's confidence score.
Model diversity beats model capability. That insight may be worth more than the tool.
How loop actually wires the two agents together
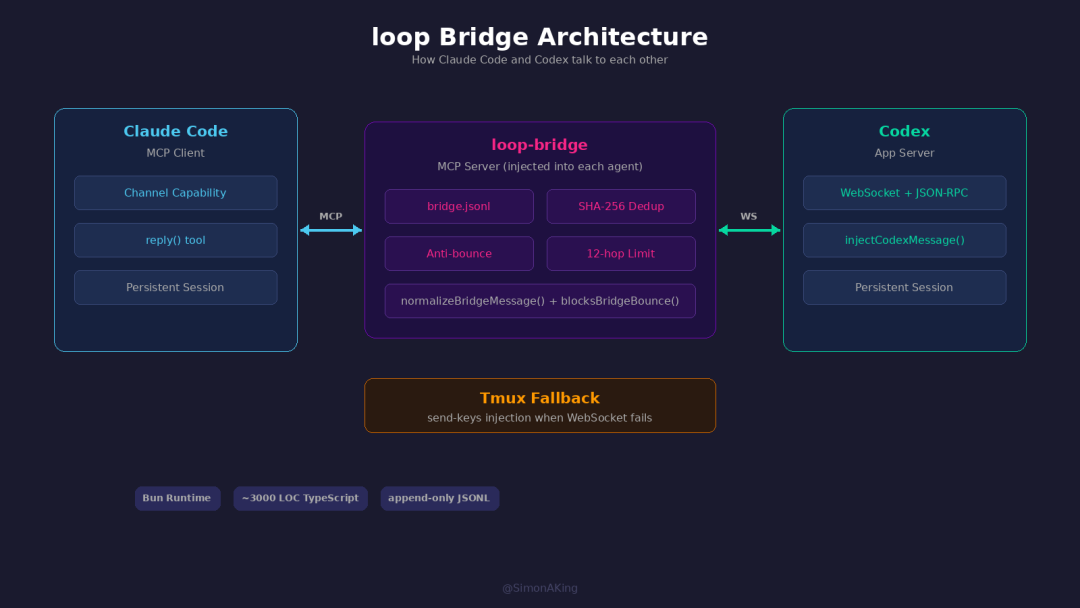
loop: a bridge relays messages between two independent agent processes.
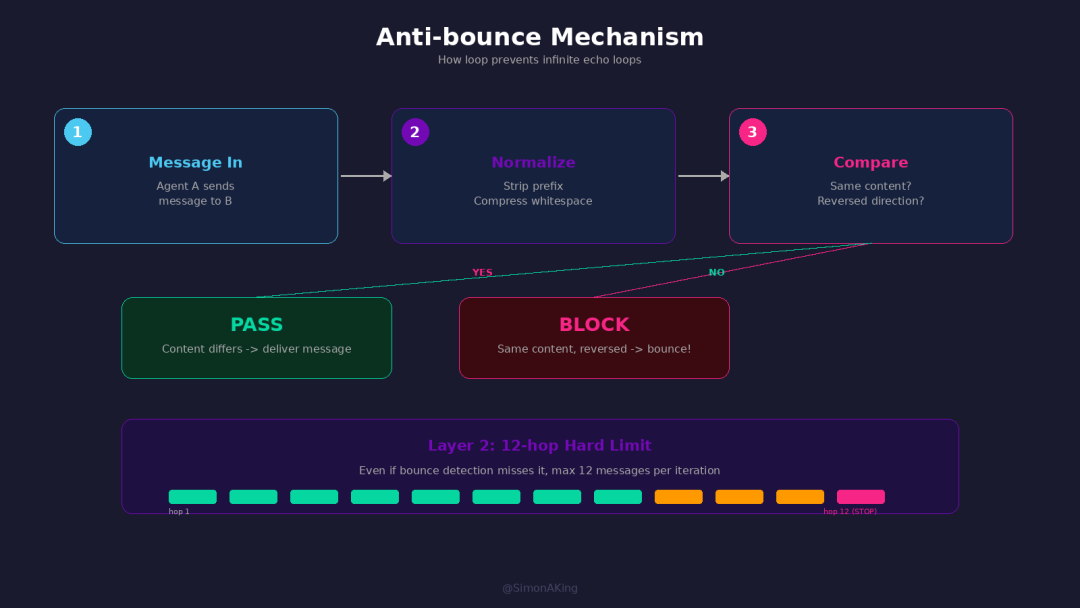
loop's anti-bounce: bounce detection plus a 12-hop cap stop the infinite mutual-agreement loop.
loop's core problem is simple: Claude Code and Codex are two completely independent processes. No shared memory, no public API. How do they talk?
Bridge: an MCP relay. loop injects an MCP Server into each agent — loop-bridge. What Claude says gets translated through the bridge into a format Codex can ingest, and vice versa. Two speakers of different dialects, one translator in the middle.
Concretely: on the Claude side, loop uses Claude Channel — Codex's messages arrive as channel notifications and Claude replies with the reply tool. On the Codex side, loop uses App Server mode — WebSocket + JSON-RPC, with loop injecting messages into Codex's thread.
Message storage: boring but effective. Persistence is the simplest possible primitive — a bridge.jsonl file, append-only, one line per message. Each message is signed with SHA-256(sender>receiver + content) to prevent duplicate delivery. No database. The design philosophy is lightweight — 3,000 lines of TypeScript, Bun runtime, one jsonl file. Enough is enough.
Anti-bounce: stop the infinite mutual-agreement loop. Two AIs in conversation actually fall into loops. Claude says "there's a race condition here." Codex says "yes, there is a race condition." Claude says "correct, I noticed it too." Forever.
loop's solution is two layers. Layer one — bounce detection: before sending each message, check the recipient's most recent delivered message. If normalised content (strip prefix, compress whitespace) matches and direction reversed (A→B's content = B→A's), intercept. The normalisation is only text-level, easy to bypass with a word change. So layer two — a 12-hop cap. Each round of bridge passes at most 12 messages before forcibly stopping and moving to the next iteration. One layer catches duplicates, one layer catches chatterboxes. Not perfect; with a 3K-LOC budget, enough.
Paired Loop workflow. The full flow: two agents start with persistent sessions. The main agent (Codex by default) takes the task and starts writing. After each round it drains bridge messages (up to 12 hops). On a done signal it enters review. Clever bit: in claudex mode, Claude and Codex review in parallel; both reviews go to the main agent at once. If both reviewers flag the same issue, the main agent prioritises that fix. That's where the 100% adoption rate comes from. After both reviewers PASS, a Draft PR is auto-created.
tmux fallback. If the WebSocket channel fails, loop falls back to sending keystrokes directly to the tmux pane — essentially simulating a human typing. Crude, but it keeps communication alive.
Beyond loop: the multi-agent coding map

The multi-agent coding landscape, H1 2026.
loop isn't alone. H1 2026 is a multi-agent coding tools explosion.
Tier 1: official capabilities from the big three
Claude Code Agent Teams. Anthropic's official answer. One Claude Code session acts as team lead, assigns work to multiple sub-agents, coordinates and aggregates. Each sub-agent is its own Claude Code instance with its own context and tool permissions. Difference from loop: Agent Teams is same-model multi-instance; loop is different-model cross-harness. The former solves "one person can't finish". The latter solves "one person can't see everything."
Codex Multi-Agent. OpenAI's answer. Codex evolved from a coding agent into a multi-agent dev platform — multiple agents handle different tasks in parallel. Architecturally tilted toward long-running workflows and orchestration.
VS Code Multi-Agent (1.109). Microsoft's January 2026 release ships Claude, Codex, and Copilot side-by-side. The Agent Sessions panel unifies session management — local, background, cloud. $10/mo runs three agents.
Cursor Background Agent. Cursor 2.0 added Background Agent — hand a task to a cloud agent, async. Plus mid-session model swapping (GPT-5.3-Codex, Claude Sonnet 4.5, Gemini 3 Pro) — multi-model collaboration in another form.
Tier 2: the open-source flowering
- AMUX (Agent Multiplexer). Open-source Claude Code multiplexer. Runs dozens of agents in parallel, each in its own tmux pane. Web dashboard for real-time status. The toughest feature: a self-healing watchdog that compacts an agent's context when usage drops below 20%, preventing the window from blowing up. SQLite kanban prevents multiple agents repeating work.
- dmux (Dev Agent Multiplexer). Another open-source multiplexer. Key difference: each agent runs in its own git worktree, sidestepping file conflicts by construction. Suited to splitting a large task into independent subtasks.
- claude-octopus. Multi-LLM orchestration plugin for Claude Code. Schedules 8 providers (Codex, Gemini, Perplexity, OpenRouter, Copilot, Qwen, Ollama). 47 commands, 50 skills. The interesting bit: a 75% consensus threshold — a change ships only if 75%+ of the models agree. Same idea as
loop's 100% adoption rate — replace single-model confidence with multi-model consensus. - claude-code-bridge. Real-time collaboration across Claude, Codex, and Gemini. Persistent context and daemon mode (auto-shuts after 60s idle). Codex can delegate subtasks to OpenCode agents.
- Pair Programmer (VideoDB). Completely different angle. Doesn't pair AIs to each other — pairs the AI to your screen. Records your screen, mic, and system audio in real time. AI can answer natural-language queries like "what file was I looking at when I mentioned the auth bug?" Closes the info gap between human and AI.
Conductor vs Orchestrator
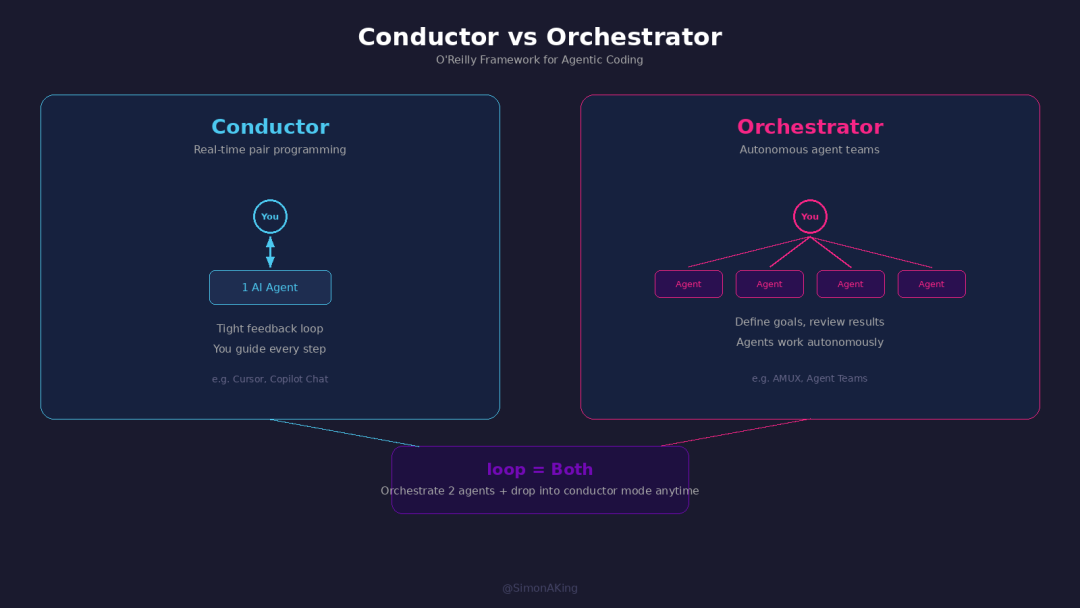
From conductor to orchestrator: the developer's role shifts from implementer to manager.
O'Reilly's recent piece Conductors to Orchestrators: The Future of Agentic Coding draws a useful frame:
Conductor. You and one AI in tight coordination, guiding each step in real time. Cursor's mode — you write a prompt, AI changes code, you check, you adjust. You stay in the loop the whole time.
Orchestrator. You define a top-level goal and decomposition. Multiple AI agents execute autonomously. You don't care how each line gets written — only whether the final result is correct. AMUX running a dozen agents while you only review and merge.
loop is interesting because it sits between the two — it's an orchestrator (coordinating two agents) but you can drop into conductor mode at any time (just talk to either agent in tmux). That hybrid may be the most practical shape at this stage of the cycle.
The developer's role is shifting from implementer to manager. The question moves from "how do I write this code" to "how do I ensure the right code gets written." Subtle, but profound.
Agentmaxxing — where's the ceiling?
A new word in the community: agentmaxxing — running as many AI coding agents as you can in parallel, each on a different task, while you only review and merge.
In practice the cap is around 5–7 concurrent agents. Past that, rate limits, merge conflicts, and review bottlenecks eat the gains. You can run 20 agents. You can't review 20 PRs.
This exposes a deeper truth: the bottleneck in multi-agent coding isn't on the agent side. It's on the human side. Agents scale infinitely; human attention bandwidth is fixed.
Two directions to break the ceiling:
- Agent self-review.
loop'sclaudexreview is exactly this — have agents review each other, only surface consensus issues to the human. Cuts the information load you have to process. - Better dashboards. AMUX's web dashboard, VS Code's Agent Sessions panel — both try to compress the state of many agents into a density humans can scan.
Four trend judgements
1. Multi-harness is the direction. More and more people are running Claude Code + Codex + Cursor + Gemini CLI concurrently — not for benchmarking but because different models have different blind spots. The trend accelerates. Cross-harness interop (what loop is doing) becomes a requirement.
2. Consensus mechanisms get more important. loop's 100% adoption rate, claude-octopus's 75% threshold, claudex parallel review — all pointing at the same thing: multi-model voting is more reliable than single-model verdicts. Expect a standardised "AI consensus protocol" to emerge.
3. Agent communication needs a standard. Every tool is rolling its own bridge. loop uses MCP + jsonl. claude-code-bridge uses daemon mode. claude-octopus has its own router. The field is missing a standard protocol. MCP is the best candidate; it isn't there yet.
4. The human role is changing, not disappearing. From writing code to directing AI to writing code, to managing AI teams. The job shape changes — understanding requirements, making decisions, judging quality become more important, not less. The ceiling on agentmaxxing isn't agent count. It's human-judgement bandwidth.