Part 1 of 3. Part 2 — setup, accounts, settings, opusplan, context management →. Part 3 — workflow, CLAUDE.md, MCP, .claude folder, cross-review with Codex →.
Claude Code is probably the most loved-and-hated dev tool of 2026.
Last week Anthropic admitted on Reddit: "Users are hitting rate limits much faster than we expected." Max users ($200/mo) report burning 5 hours of quota in 19 minutes. Some report only 12 working days out of 30. Someone says a "hello" ate 2% of their session quota. Someone reverse-engineered the Claude Code binary on GitHub and found two prompt-cache bugs silently inflating token consumption by 10–20×.
Our team burned 25.2 billion tokens on Claude Code — Sub2API backend below, API-equivalent cost $22,950. We used those tokens to build Mana — a platform that lets users create native iPhone apps in natural language. 13+ hours a day on Claude Code, two Max x20 accounts in rotation, hundreds of millions of tokens a day is normal.
We've been dealing with these problems from day one. What follows is what 25B tokens taught us.
How wild is this tool, really?
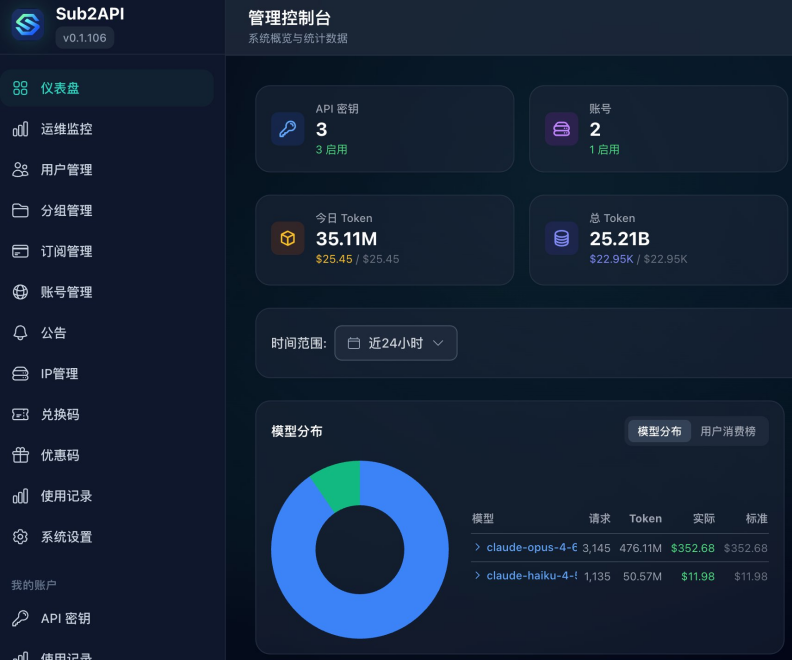
Sub2API dashboard: 25.2 billion tokens consumed, $22,950 API-equivalent cost.
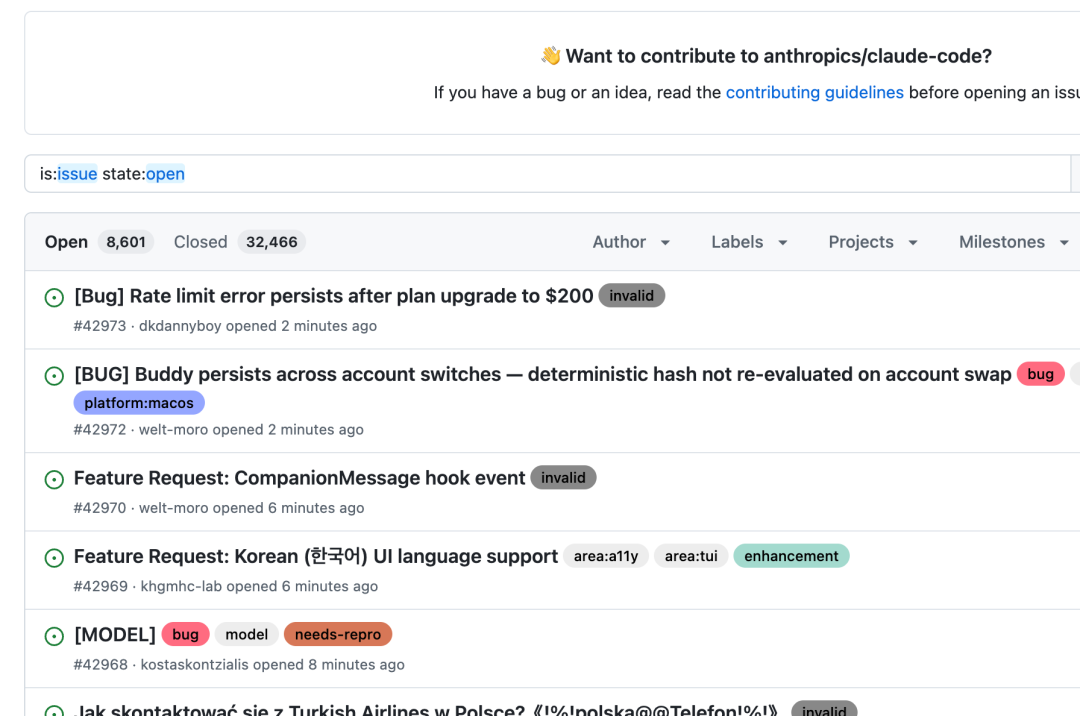
Claude Code's GitHub issue tracker: 8,000+ open issues, 2,000+ new per week.
One number first: 25.2B tokens. API-equivalent cost $22,950. Enough to buy a car if it had been API-billed instead of subscription.
But that's not the point. The point is — Claude Code doesn't want you to know how much you're burning.
Type /cost, it tells you "subscription users don't need to worry about cost." Anthropic publishes zero specific token quotas for any plan. They only say "Pro is 5× the free version." Five times what? They won't tell you.
Someone reverse-engineered the Claude Code binary and found two bugs that invalidate the prompt cache — silently ballooning real token consumption by 10–20×. Downgrading to the older 2.1.34 noticeably fixed it.
How bad has the community frustration gotten? Max 20x users ($200/mo) reporting 5-hour windows burned in 19 minutes. A "hello" eating 2% of session quota. "In 30 days I got 12 usable days." Someone posted an open letter on GitHub titled "Critical: Widespread abnormal usage limit drain" — "I filed a ticket, nobody responded. I tweeted, nobody responded. The only official response on Reddit was 'we're investigating.'"
March 31. Anthropic admits: "users are hitting limits much faster than we expected."
The GitHub issue tracker is a disaster. 6,000+ open issues, 3,554 tagged as bugs. 2,000–2,500 new issues per week. Analysis shows 49–71% of closures are bot-driven — Anthropic uses Opus 4.6 for classification, a dedupe bot to mark duplicates, then auto-closes. Issues marked "duplicate" are auto-locked and closed, and the "original" issue they point at is often itself already closed.
An ECONNRESET bug first reported December 2025 was still being closed-and-reopened in March 2026. Someone counted 12 related issues, 70+ community comments providing root-cause analysis, zero replies from Anthropic engineers. There's an entire HN thread about it: Claude Code's issue page auto-closes after 60 days of inactivity; the comments section is a chorus of boos.
Same day, Claude Code's 510K lines of source were accidentally published to npm because .npmignore was missing a .map file. This is the second time — the same thing happened in February 2025. The leaked source contains a system called "Undercover Mode" specifically to prevent AI from leaking internal info in git commits. Anthropic then published the entire source itself.
The leaked source did make the product look impressive: three-layer memory compression, 42 on-demand tools, KAIROS autonomous background daemon, ULTRAPLAN remote cloud planning. VentureBeat: "This isn't an LLM wrapper. It's a complete software engineering operating system."
My read is the same: Claude Code is the best AI coding tool right now, no question. But Anthropic's operations don't match the product.
The dumbing-down is real, not in your head
Quick technical fact: Anthropic officially admitted in August 2025 that due to inference-stack updates, Opus 4.1 and Opus 4.0 experienced real quality degradation. Root cause was an XLA compiler bug — the model computed next-token probabilities in bf16 but TPU needs fp32, the precision mismatch meant the model often missed the "optimal" token. A tiny probability skew, accumulated over hundreds of generations, becomes a large drop in output quality.
In English: Claude was about to say "?" but, because of bad arithmetic, said "." instead. One or two times doesn't matter. After a few hundred, the whole output is mush.
That was rolled back. In March 2026, similar things returned:
- status.claude.com records. March 21: Opus 4.6 and Sonnet 4.6 mass error spike. March 26–27: network performance degradation, service outage. March 31 to April 1: Opus and Sonnet request timeouts spike.
- Community testing. "Smooth at 2am. Heavily throttled during peak day hours." Not dumbing-down — Anthropic quietly degrades service quality during peak.
- Version downgrade works. Downgrade Claude Code from latest to 2.1.34, token consumption returns to normal. So it's not that the model got dumber — the client code has bugs.
The "dumbing-down" split: roughly a third real model regression, a third prompt-cache invalidation blowing up tokens (context truncated → quality drops), a third peak-hour throttling.
How to deal with it:
- Install CodexBar to monitor usage. Catch abnormal consumption fast.
- Watch status.claude.com. Don't push through an incident. Swap to off-peak, or switch to Codex for the duration.
- If it feels obviously dumber,
/clearfirst. Likely context built up to auto-compact, truncated and lost key info. - Peak-hour expectations (US east 8am–2pm) down. Or work off-peak.
- If a version has bugs, downgrade.
npx @anthropic-ai/claude-code@2.1.34runs a specific version.
80% of your tokens are silently wasted
My judgement: for most people, at least half of token consumption on Claude Code is unnecessary. Four main token traps:
1. Context snowball. Claude Code keeps conversation continuity by reloading all history and uploaded files on each interaction. The longer the conversation, the more tokens per request — snowball growth. The irony — past a certain length, the model starts dumbing down. It forgets earlier instructions, logic blurs. You pay more for worse results.
2. Wrong model. Opus is several times more expensive than Sonnet, but for most day-to-day coding the capability gap is much smaller than the price gap. I've seen too many people open Opus from minute one and write CSS in Opus. Totally unnecessary.
3. MCP tool hidden cost. Install many MCP servers (Chrome DevTools, databases, plugins), every tool definition gets injected into context. Real data: MCP tool descriptions can eat 10% of your context window — before you've done any work.
4. Same-context multi-task pollution. Doing two unrelated tasks back-to-back in one session means the auth-bug context is still in memory while you ask for a UI component. The model has to remember the useless and understand the new. Both halves get worse.
This is where the workflow piece comes in — and that's part 2.
Continue: Part 2 — setup, accounts, settings, opusplan, context management →